
O disco que não pode falhar, mas vai
Em qualquer servidor, o armazenamento é o componente com a maior taxa histórica de falhas. Um disco rígido tem vida útil medida em horas de operação; SSDs têm ciclos de escrita limitados; controladoras RAID ficam obsoletas. A questão não é se o disco vai falhar, é o que acontece com seus dados quando isso ocorre.
Em clusters Proxmox, esse problema ganha outra dimensão: quando você tem dezenas de máquinas virtuais distribuídas entre vários nós físicos, onde ficam os dados dessas VMs? Se os dados de uma VM estão em um único servidor e esse servidor falha, a VM inteira vai junto.
A resposta para esse problema tem nome: Ceph.
“O Ceph não elimina falhas de hardware. Ele as torna irrelevantes.”
O que é o Ceph
Ceph é um sistema de armazenamento distribuído de código aberto projetado para uma premissa simples: hardware vai falhar, então construa o software para assumir isso como padrão, não como exceção.
Em vez de armazenar dados em um único local, o Ceph fragmenta os dados, cria múltiplas cópias e as distribui automaticamente entre todos os discos do cluster. Quando um disco ou servidor falha, o Ceph detecta a ausência, usa as cópias distribuídas para manter o acesso e inicia automaticamente o processo de re-replicação para restaurar o número de cópias configurado.
Tudo isso acontece de forma transparente, sem intervenção manual.
O Ceph oferece três interfaces de acesso ao mesmo pool de dados subjacente, o RADOS. Cada interface resolve um problema diferente, mas todas compartilham a mesma camada de armazenamento distribuído por baixo.
RADOS Block Device (RBD)
O RBD expõe o armazenamento Ceph como dispositivos de bloco: do ponto de vista do sistema operacional ou do hipervisor, é como se fosse um disco físico conectado diretamente, mas na prática esse “disco” existe distribuído entre todos os OSDs do cluster.
Para o Proxmox, o RBD é a interface central. Cada disco virtual de uma VM é um image RBD armazenado no pool Ceph. Quando o Proxmox cria uma VM com 100 GB de disco, ele cria um image RBD de 100 GB que é automaticamente replicado entre os nós conforme o fator de replicação configurado. Esse disco pode ser acessado por qualquer nó do cluster, o que é o que viabiliza o Live Migration e o HA.
O RBD também suporta snapshots e clones nativos: criar um snapshot de um disco de VM é uma operação instantânea no Ceph, sem necessidade de pausar a VM ou copiar dados. Clonar um image (criar uma nova VM a partir de um template, por exemplo) também é uma operação leve. O clone compartilha os blocos com o original até que uma escrita ocorra, economizando espaço.
Fonte: RADOS Block Device (RBD). Documentação oficial do RBD, cobrindo snapshots, clones, integração com QEMU/KVM e mapeamento de dispositivos.
Ceph File System (CephFS)
O CephFS expõe o armazenamento Ceph como um sistema de arquivos distribuído, acessível via montagem padrão em Linux. É a interface adequada para dados que precisam ser compartilhados entre múltiplas VMs simultaneamente, como diretórios home, repositórios de mídia ou dados de aplicações que rodam em cluster.
O CephFS é o único componente do Ceph que depende do MDS (Metadata Server), o daemon responsável por gerenciar a estrutura de diretórios e permissões. Para o uso de RBD com Proxmox, o CephFS e o MDS não são necessários.
Fonte: Ceph File System (CephFS). Documentação oficial do CephFS, incluindo arquitetura do MDS, montagem em Linux e casos de uso de sistemas de arquivos distribuídos.
RADOS Gateway (RGW)
O RGW expõe o armazenamento Ceph como um serviço de objetos compatível com as APIs S3 da Amazon e Swift da OpenStack. Do ponto de vista de uma aplicação, conectar no RGW é idêntico a conectar no Amazon S3, com os mesmos SDKs, as mesmas ferramentas e os mesmos protocolos.
Isso torna o RGW especialmente útil para:
- Backups automatizados: ferramentas como Restic, Rclone, Velero e Proxmox Backup Server podem armazenar backups diretamente no RGW como se fosse um bucket S3, sem depender de serviços externos pagos
- Armazenamento de arquivos estáticos: imagens, logs, artefatos de build e qualquer dado que não precisa de acesso de bloco ou de sistema de arquivos
- Migração de workloads cloud para on-premise: aplicações que já usam S3 podem ser apontadas para o RGW sem alteração de código, mantendo os dados dentro da infraestrutura do provedor
Para provedores que já operam um cluster Ceph para as VMs, adicionar o RGW é uma forma de oferecer armazenamento de objetos como serviço interno sem nenhum hardware adicional, já que o pool de dados já existe e é compartilhado.
Fonte: RADOS Gateway (RGW). Documentação oficial da interface de objetos do Ceph, incluindo compatibilidade com S3/Swift, autenticação e configuração de buckets.
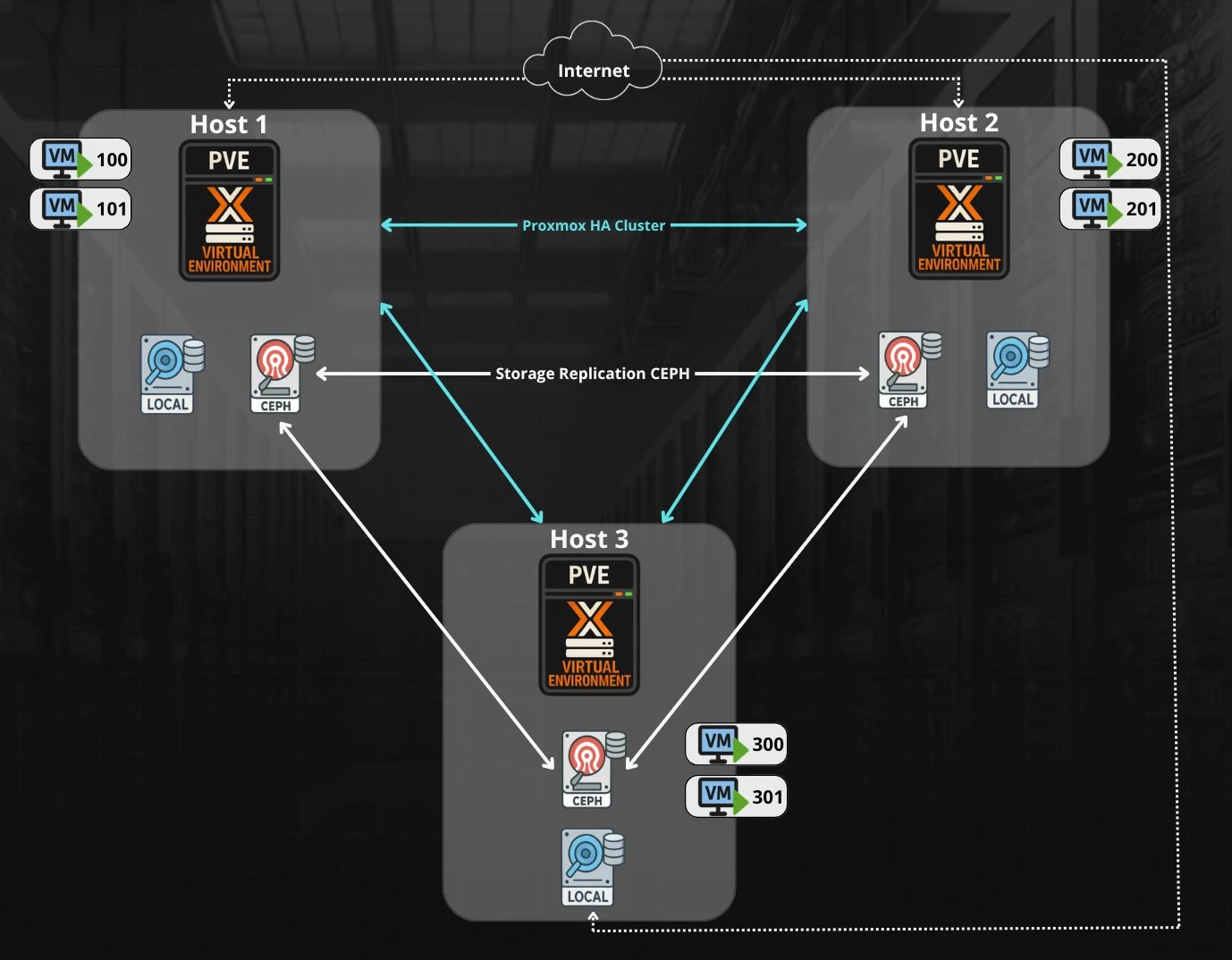
Por que Ceph no Proxmox muda tudo
Em um cluster Proxmox sem Ceph, cada servidor é uma ilha. Os discos de uma VM pertencem ao nó onde ela roda. Se esse nó falha, a VM para, e só volta quando o nó voltar. Operações de manutenção exigem janelas de downtime agendadas.
Com Ceph, essa lógica se inverte. O disco de uma VM não pertence a nenhum servidor: ele existe no pool distribuído do cluster inteiro. Qualquer nó pode acessar qualquer VM a qualquer momento. Isso habilita dois recursos que transformam a operação de um cluster Proxmox:
Live Migration é a capacidade de mover uma VM em execução de um servidor físico para outro, sem desligar, sem interrupção perceptível para quem usa o serviço. Como os dados já estão no Ceph e acessíveis de qualquer nó, o que precisa ser transferido é apenas o estado da memória RAM, uma operação que leva segundos.
Alta Disponibilidade (HA) automático significa que quando um nó falha, o Proxmox detecta a ausência e reinicia as VMs afetadas em outros nós do cluster, automaticamente, sem intervenção humana. Em média, VMs recuperadas em 1 a 2 minutos após a detecção da falha.
Sem armazenamento compartilhado, esses dois recursos simplesmente não existem. Com Ceph, eles funcionam nativamente, integrados à interface do Proxmox.
Fontes: Migration of VMs and Containers e High Availability. Documentação oficial do Proxmox VE sobre Live Migration e o HA Manager.
Arquitetura: os componentes do Ceph
Um cluster Ceph é composto por daemons com funções bem definidas. Entender o papel de cada um é fundamental para compreender como o sistema garante resiliência.
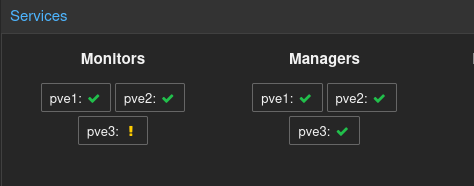
Monitor (MON)
O MON é o guardião do estado do cluster. Ele mantém o cluster map: um registro completo de quais discos existem no cluster, quais estão saudáveis, quais falharam e como os dados estão distribuídos entre eles.
Para que o cluster funcione, os MONs precisam estar em quorum, maioria simples ativa. Por isso, o número mínimo recomendado é três MONs, com um falhando, os dois restantes formam maioria e o cluster continua operando normalmente. Com apenas dois MONs, basta um falhar para que o restante perca a maioria e o cluster paralise.
Em clusters Proxmox, o padrão é cada nó do cluster hospedar um MON.
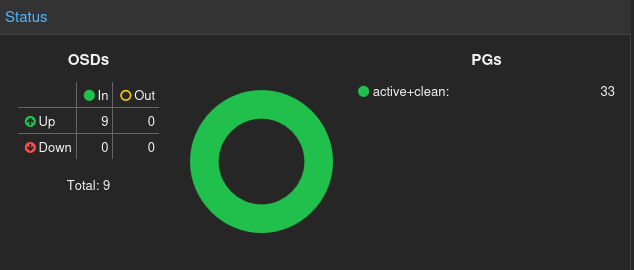
Object Storage Daemon (OSD)
O OSD é onde os dados realmente vivem. Cada disco físico dedicado ao Ceph roda um daemon OSD responsável por armazenar os dados, replicar as cópias para outros OSDs e reportar falhas aos MONs.
A regra de ouro é um OSD por disco físico. Colocar múltiplos OSDs no mesmo disco destrói o isolamento de falha que é a razão de ser do Ceph.
Manager (MGR)
O MGR complementa os MONs com funções de monitoramento, dashboard e integração com ferramentas externas como Prometheus e Grafana. Não armazena dados. É a camada de observabilidade e gestão do cluster. O Proxmox utiliza o MGR para expor métricas de IOPS, latência e capacidade diretamente na interface.
Metadata Server (MDS)
O MDS só entra em cena quando se usa o CephFS, o sistema de arquivos distribuído do Ceph. Para uso de discos de VM via RBD no Proxmox, o MDS não é necessário.
O algoritmo CRUSH: onde cada dado vai parar
O coração do Ceph é o CRUSH (Controlled Replication Under Scalable Hashing). É ele que decide onde cada pedaço de dado é armazenado e como as cópias são distribuídas entre os OSDs.
A lógica é elegante: dado o identificador de um objeto e o mapa atual do cluster, qualquer nó consegue calcular sozinho onde esse dado está, sem precisar perguntar a nenhum servidor central. Isso elimina o gargalo clássico de sistemas de armazenamento distribuído que dependem de um metadados centralizado para localizar dados.
O CRUSH também aplica regras de domínios de falha (failure domains): você configura para que cópias do mesmo dado nunca fiquem no mesmo disco, no mesmo servidor, no mesmo rack ou no mesmo datacenter. Com domínio de falha por servidor e três cópias, a falha completa de um nó físico não coloca nenhum dado em risco. As outras duas cópias permanecem acessíveis em servidores diferentes.
Fontes: CRUSH Map. Configuração de domínios de falha e hierarquias na documentação oficial do Ceph. Paper original: Weil et al., CRUSH: Controlled, Scalable, Decentralized Placement of Replicated Data, SC’06.
Fator de replicação: quantas cópias dos dados?
O fator de replicação define quantas cópias de cada dado o Ceph mantém simultaneamente no cluster. É o principal trade-off entre resiliência e aproveitamento de espaço.
| Cópias | Falhas toleradas | Nós mínimos | Overhead de espaço |
|---|---|---|---|
| 2 cópias | 1 nó | 2 | 2× (50% de aproveitamento) |
| 3 cópias | 1 nó com leitura e escrita | 3 | 3× (33% de aproveitamento) |
| 3 cópias + min 1 | 2 nós (somente leitura) | 3 | 3× (33% de aproveitamento) |
O padrão recomendado para produção é três cópias, com o cluster aceitando leituras e escritas enquanto ao menos duas cópias estejam acessíveis. A falha de um nó inteiro não interrompe operações.
💡 O overhead é inevitável. Com três cópias, para cada 1 TB de dados úteis você precisa de 3 TB de disco raw no cluster. Planejar a capacidade real levando em conta o fator de replicação é um passo fundamental em qualquer projeto com Ceph.
O que o Ceph exige de infraestrutura
O Ceph é tolerante a falhas de hardware, mas exigente com a qualidade da rede e com o dimensionamento correto dos recursos. Entender esses requisitos evita os problemas mais comuns em implantações.
Rede é o componente mais crítico. O tráfego interno de replicação do Ceph é intenso e constante: cada escrita de dado é replicada imediatamente para os outros OSDs. Por isso, a recomendação padrão é rede de 10 Gbps entre os nós, e separação em duas redes distintas, uma para o tráfego entre VMs e OSDs (rede pública), outra exclusiva para a replicação interna entre OSDs (rede de cluster). Misturar os dois tráfegos em uma única interface de 1 Gbps é a causa mais comum de performance insatisfatória.
Discos dedicados para OSDs. O Ceph não funciona bem dividindo um disco com o sistema operacional. Cada disco entregue ao Ceph precisa ser exclusivo. Uma configuração comum em produção é usar HDDs para os dados e SSDs/NVMe separados para acelerar as operações de metadados do BlueStore, o backend de armazenamento padrão do Ceph moderno.
RAM proporcional ao número de OSDs. O consumo de memória cresce com o cluster. A referência prática é reservar entre 1 e 2 GB de RAM por OSD, mais a memória necessária para o Proxmox e as VMs que rodam no mesmo nó.
Como o Ceph reage a falhas
Uma das características mais importantes do Ceph é o comportamento autônomo e progressivo diante de falhas. Quando um OSD ou servidor fica indisponível:
- Os OSDs vizinhos detectam a ausência e reportam aos MONs
- O cluster entra em estado de alerta (
HEALTH_WARN) mas continua operando normalmente, pois as cópias nos outros nós absorvem o acesso - O Ceph aguarda alguns minutos antes de iniciar a re-replicação, para não desperdiçar esforço em reinicializações rápidas
- Se o OSD não voltar dentro do prazo, o Ceph redistribui automaticamente os dados pelos OSDs restantes, restaurando o fator de replicação configurado
Essa recuperação é automática, sem intervenção humana. O operador recebe o alerta, tem tempo para agir, e o cluster mantém os dados seguros durante todo o processo.
🔍 Visibilidade total: o Ceph expõe métricas nativas para Prometheus. Com Grafana, é possível acompanhar em tempo real o estado de cada OSD, IOPS por pool, latência de leitura e escrita, e capacidade utilizada, tudo integrado à stack de monitoramento do Proxmox.
Referência: Ceph Health Checks. Lista completa dos estados de saúde e seus significados na documentação oficial do Ceph.
O lado difícil do Ceph
O Ceph resolve um problema real e resolve bem. Mas seria desonesto falar dele sem abordar as dificuldades que aparecem na prática. Muitos ambientes chegam ao Ceph esperando uma solução plug-and-play e descobrem, na operação do dia a dia, que ele exige um nível de comprometimento que vai muito além da instalação.
Complexidade operacional
O Ceph é um dos sistemas distribuídos mais complexos disponíveis em código aberto. A curva de aprendizado é íngreme: conceitos como Placement Groups, CRUSH maps, BlueStore, pools de replicação e erasure coding não têm equivalente direto em soluções de storage tradicionais. Um time que nunca operou Ceph antes vai encontrar uma documentação extensa e comportamentos que exigem entendimento profundo para diagnosticar corretamente.
⚠️ O risco do cluster “funcionando mal sem ninguém perceber”. Um cluster Ceph pode operar em estado
HEALTH_WARNpor semanas sem impacto perceptível nas VMs, até que uma segunda falha aconteça e a margem de segurança já não exista. Monitoramento ativo não é opcional em ambientes Ceph.
O custo real de armazenamento
O overhead de 3x no fator de replicação padrão significa que, em um cluster com 30 TB de disco raw, apenas 10 TB ficam disponíveis para dados. Na prática, o aproveitamento real é ainda menor: o Ceph recomenda não ultrapassar 70% a 80% de ocupação do cluster para preservar a capacidade de rebalanceamento em caso de falha.
Isso significa que 30 TB raw → ~7 TB utilizáveis com segurança em produção. Para quem dimensiona a capacidade olhando apenas para os discos físicos, o resultado na entrega costuma ser uma surpresa desagradável.
Sensibilidade à rede
O Ceph foi projetado assumindo rede de alta velocidade e baixa latência entre os nós. Qualquer degradação de rede, seja por saturação de link, por switches de baixa qualidade ou por instabilidade, se traduz diretamente em latência de escrita para as VMs. Em redes de 1 Gbps compartilhadas com outros tráfegos, o comportamento do Ceph em produção raramente atinge as expectativas.
O cenário mais crítico é o rebalancing storm: quando um nó é adicionado ou removido do cluster, o CRUSH redistribui os Placement Groups entre os OSDs. Em clusters grandes, esse tráfego pode saturar completamente os links de rede e impactar as VMs em produção.
Ceph e o ecossistema Proxmox
A integração entre Ceph e Proxmox vai além de “adicionar um storage”. O Proxmox trata o Ceph como um componente nativo do hipervisor, com suporte direto na interface web para criar e gerenciar OSDs, pools, MONs e MGRs, sem precisar de linha de comando para operações do dia a dia.
Essa integração é o que conecta o Ceph aos dois recursos mais valorizados em ambientes de alta disponibilidade:
Live Migration: com os discos das VMs no pool Ceph, mover uma VM entre nós em produção é uma operação rotineira. O Proxmox transfere apenas o estado da memória RAM enquanto a VM continua em execução. É o que viabiliza atualizações de hardware e balanceamento de carga entre servidores sem janelas de manutenção.
HA automático: o Proxmox HA monitora os nós do cluster via heartbeat. Quando um nó falha, o gerenciador de HA verifica quais VMs estavam rodando nele, confirma que os dados estão acessíveis via Ceph e as reinicia nos nós disponíveis. O processo é automático, auditável e configurável por grupo de prioridade.
Fonte: Proxmox VE: Ceph Server. Guia oficial de instalação, configuração e operação do Ceph integrado ao Proxmox VE.
Quando faz sentido adotar o Ceph
O Ceph é uma escolha sólida para ambientes que combinam algumas condições:
- Três ou mais nós físicos no cluster. Com menos de três, o quorum de MONs não funciona adequadamente
- Rede de 10 Gbps dedicada entre os nós, pois a replicação síncrona exige largura de banda consistente e previsível
- Discos exclusivos para OSDs separados do disco do sistema operacional, sem compartilhamento de IOPS com outros processos
- Necessidade real de Live Migration ou HA que justifique o overhead de armazenamento e a complexidade operacional
- Equipe com capacidade de operar o ambiente, com monitoramento ativo e conhecimento para diagnosticar alertas e intervir quando necessário
Quando essas condições estão presentes, o Ceph entrega o que promete: armazenamento resiliente, integrado ao Proxmox, com Live Migration e HA funcionando de forma nativa.
Cenários onde o Ceph não é a escolha ideal
Reconhecer quando o Ceph não é a solução certa é tão importante quanto saber quando é. Alguns cenários onde outras abordagens fazem mais sentido:
Cluster de dois nós. É o cenário mais comum onde o Ceph decepciona. Com apenas dois nós, não há quorum adequado para os MONs, e a própria premissa de domínio de falha por servidor fica comprometida: com duas cópias em dois servidores, a falha de um nó deixa o cluster sem margem. O Proxmox oferece replicação de storage via ZFS entre dois nós, sem os requisitos de rede e sem Live Migration, mas com failover funcional e muito menos complexidade.
Rede de 1 Gbps entre os nós. Montar Ceph em ambiente com links de 1 Gbps é tecnicamente possível, mas operacionalmente frustrante. A replicação consome banda constantemente; durante um rebalanceamento, a rede satura e as VMs sofrem. Antes de instalar o Ceph, a pergunta correta é: a infraestrutura de rede suporta a carga de replicação sem impactar o tráfego de produção?
Capacidade de armazenamento muito limitada. Se o orçamento permite apenas 3 discos de 2 TB no cluster inteiro, o Ceph vai entregar menos de 2 TB utilizáveis com segurança, e para isso vai exigir toda a infraestrutura de rede e a carga operacional de um sistema distribuído. Nesse cenário, um único servidor com RAID e backup offsite entrega mais capacidade com menos complexidade.
💡 A escolha da solução de storage deve ser proporcional ao nível de disponibilidade exigido e à capacidade do time de operar o ambiente. Ceph é a opção mais robusta, mas robusto e simples são coisas diferentes, e subestimar a complexidade operacional é o erro mais comum em implantações mal-sucedidas.
Conclusão: uma tecnologia poderosa para quem está pronto para ela
O Ceph resolve um problema genuíno e resolve bem: elimina o storage como ponto único de falha em clusters Proxmox, habilita Live Migration real e torna o HA automático possível. Para ambientes que precisam dessas capacidades e têm a infraestrutura para suportá-las, é difícil encontrar alternativa equivalente em código aberto.
Mas o Ceph não é uma solução de infraestrutura que se instala e esquece. Ele exige rede adequada, hardware dimensionado corretamente, monitoramento ativo e um time que entende o que está operando.
O hardware vai falhar. Discos param, servidores precisam de manutenção, updates exigem reinicializações. Com Ceph, nenhuma dessas situações precisa significar downtime para suas VMs. O sistema absorve a falha, mantém os dados acessíveis e reinicia o que precisa ser reiniciado, automaticamente.
O investimento em hardware (discos adicionais, rede 10 Gbps) é real. Mas para provedores que rodam serviços críticos em Proxmox, a pergunta não é se um disco vai falhar. É quantas VMs você pode se dar ao luxo de perder quando ele falhar.